

October 3, 2022
AI is evolving. And no, I don’t mean that robots are trying to take over the world. Not yet. I mean they are evolving in the entertainment and art industry as we know it. We have better CGI than we did in the past, the animation is at a more accessible rate than ever before with anyone being able to create animations, deepfakes are being used to replace people’s faces in videos with someone else, and if done seamlessly, can cause harm to the person’s reputation, but can also be used in a positive way to bring dead people back alive and, in videos, can seem as if they never passed in the first place. But what about audio? How can we possibly imitate someone’s audio and pretend as if THEY are the ones saying it, but in reality, they aren’t? This is where AI Speech Synthesis is introduced.
AI Speech Synthesis, also known as Text-To-Speech, is a form of technology that enables text to be converted into speech sounds that can imitate the human voice. According to readspeaker.ai, “Mechanical attempts at synthetic speech date back to the 18th century. Electrical synthetic speech has been around since Homer Dudley’s Voder of the 1930s. But the first system to go straight from text to speech in the English language arrived in 1968 and was designed by Noriko Umeda and a team from Japan’s Electrotechnical Laboratory.” However, can Text to Speech actually cause chaos in our society? What is so good about Text to Speech?
Some benefits from Text to Speech are that movie producers are able to bring an artist’s voice back to life. For example, take a look at Marvel founder Stan Lee. Though he has passed, with enough voice clips, Marvel may be able to replicate his entire voice and bring him back to life in animated movies and even in real-life movies like Spider-Man. You can also use a celebrity’s voice to make a personalized message towards them. For example, take a look at the popular website Uberduck.ai. A website where anyone can type anything they desire, and they can choose which celebrity wants to say the words they typed. This can help children “talk” to their childhood figures and any idol that they desire if it is on that website. They have multiple categories, ranging from Rappers to TV shows to even Video Games for that matter. They are also constantly adding more people onto their website, so if your child has a figure they want to talk to, you can set up something for them. They also have a “singing” feature, where the AI will sing in the same melody, pitch, and rhythm chosen from reference audio. Some example reference audios that they give is the hit song from pop artist Lil Nas X, called MONTERO. You can choose any voice from any category (for example, deceased rap artist Juice WRLD), and he will sing in the exact same, pitch, and rhythm as the original song, along with the same lyrics. However, you can input your own lyrics as well, and the voice will match the melody as well. Or you can make your own reference audio by singing your own melody, and the AI will try replicating the lyrics you type in the Text-To-Speech box, as well as the melody, pitch, and rhythm you sang. This transitions over to the next point, where music industry executives and labels alike can use AI to make “artificial” songs of their deceased artists and train them so they can sound like the real thing. This could be useful for fans, who are looking for new music/movies, but this has also left room for a lot of controversy surrounding this…
Some risks from Text-To-Speech are that it can be extremely overpowered if in the wrong hands. It can cause a mass dystopia in our society if, for example, a world leader with a cult fanbase, like Donald Trump, were to have his voice replicated, someone could easily be able to say some very disturbing things, and many would likely believe that it was on his behalf as well. This would cause mass destruction and chaos in our society especially since voice clips can be easily faked, so any “leaks” many would claim to hear would simply be not true at all. For example, take a look at this website called talkobamato.me. This website can simulate former President Barack Obama being able to say anything you like with whatever you type inside the text box. Hit “Talk!” and it will mash clips of him from various places to try and replicate the word, phrase, or sentence you have tried to create. However, if you try making up complicated words, sometimes it will mash too many clips together that the word will be unrecognizable. Keep in mind though, that this software was created in April 2016. Technology has since gotten much better, and with the invention of uberduck.ai and other text-to-speech-like websites, we will see better higher quality audio, and AI may even get so advanced to the point where it can replicate human-like traits, with slurs, impediments, etc. However, right now, AI speech synthesis has a long way to go, and in the future, there may be software to combat it entirely. There could be software that points out flaws in audio that may determine whether the audio was deepfaked or not or even text-to-speech. As AI speech synthesis continues to get better, software that will be able to effectively combat it will also get better as well. Right now, though, there are obvious flaws in Uberduck.ai audio and even 15.ai, another text-to-speech software, that can be easily pointed out, and some words, phrases, and sentences can make the AI struggle, and not give out a high-quality result. Another point is that a lot of backlash will be received by the media, and even the community if movie executives and music industry executives/labels start using text-to-speech for a deceased person’s voice. Many will look at this as a quick money grab scheme for them, and they will effectively ruin the celebrity’s reputation. Take a look at deceased rapper XXXTENTACION’s posthumous releases. They have been nothing short of criticisms from critics and music fans alike, effectively ruining his reputation. This has caused many questions from fans, questioning if the deceased celebrity would approve of what posthumous releases were going out if they were alive, and if the industry executives actually care about the label and their artistry/legacy, or do they only care about the money? This has caused a number of controversies in recent years, and as more celebrities keep passing away, the use of industry AI may become very powerful for them. Heck, Text-To-Speech AI may even be more advanced at the industry level, rather than the publicly accessible ones we have right now. Movie executives and music executives can fund a LOT more money into these types of projects to keep profiting off of the celebrity’s legacy, or to try incorporating the celebrity into a project in some way, shape, or form, and try to keep their spirit alive. One last risk though, is that ANYONE can make a Text-To-Speech voice using enough voice clips and samples they are able to retrieve. For example, in the Uberduck.ai Discord server, there is a link to a website with a mapped-out tutorial on how exactly to make your own text-to-speech voice with any person of your choosing. This could be very dangerous because if someone was able to mash a bunch of voice clips of someone together, you can most likely make a very accurate text-to-speech voice, with fluent speaking as well. This could put many at danger of essentially having their voice “stolen” by somebody else, and someone possibly using the “stolen” voice to their advantage and saying anything they want essentially to blackmail them. An example of this would be where an unnamed UK-based energy firm believed that he was on a phone with his boss, and followed orders from him to transfer $243,000 to him. In reality, the voice was a deepfaked AI voice made by the fraudster. This can trick large corporations and businesses into handing frauds money, and many would question any and every audio clip we hear to see if they are fake or legitimate. The database of voices on various text-to-speech websites is growing faster than ever before, with Uberduck.ai having over 100+ voices to choose from!
So, how can YOU be safe from this? Well, first and foremost, never speak to a stranger that you do not know personally, besides any support worker. If anyone you do not know tries calling you, always be sure to verify where the call is coming from, and what their motive is for calling you. Someone could be secretly recording the conversation and trying to use your voice for their monetary gain and to trick others by using your voice. Especially in this day in age of speech recognition, many companies have features where they ask to verify it’s you via your voice. There are even some AIs out there that can clone your voice with just 5 seconds of audio in their possession. Always make sure to only interact with who you trust, and worst-case scenario, try keeping your accounts private. When answering unknown callers, never say “Hello” first or repeatedly. This can give enough data for the hacker to try calling your banks pretending to be you, and attempt to social engineer their way around and gain access to your personal information and all your financial information. Let the person on the other end of the line always attempt to talk to you first. Some scammers will wait until you say something on their end, and then after you talk, they will hang up without warning. Always verify the caller as well.
Overall, AI speech synthesis has a long way to go and is still not completely perfect. There are flaws in audio that are easily noticeable at first glance, but if you try spotting out the flaws in the audio, like mispronounced words or choppy speech, you may hear it very easily. However, technology evolves at a rapid rate, and as soon as one invention dies, another invention rises. That is just the way of the technological world. Should we worry about this right now? Maybe not, but we should in the future. At the time of this being written, the software has not fully developed yet, but a few years later down the line, big large corporations may start taking this to their advantage and start using Text-to-Speech AI for fake endorsements, or scammers may start using this to take money from people. Take a look at this explicit video of an AI speech synthesis of rapper Eminem rapping a song. It is scarily accurate how real it sounds, and many could believe that this was a real Eminem song. All in all, AI speech synthesis is a powerful tool that can be easily abused if in the wrong hands. That is why it is good to know all the precautions and safety surrounding it, and how to avoid your voice being cloned, and you can avoid having to be in a devastating situation. Please share this article with friends, family, and employers, since a single share may save millions of people having to go through this, and can inform many people as well. Please share this to anyone concerned with this topic as well, and relieve stress caused by AI speech synthesis overall.
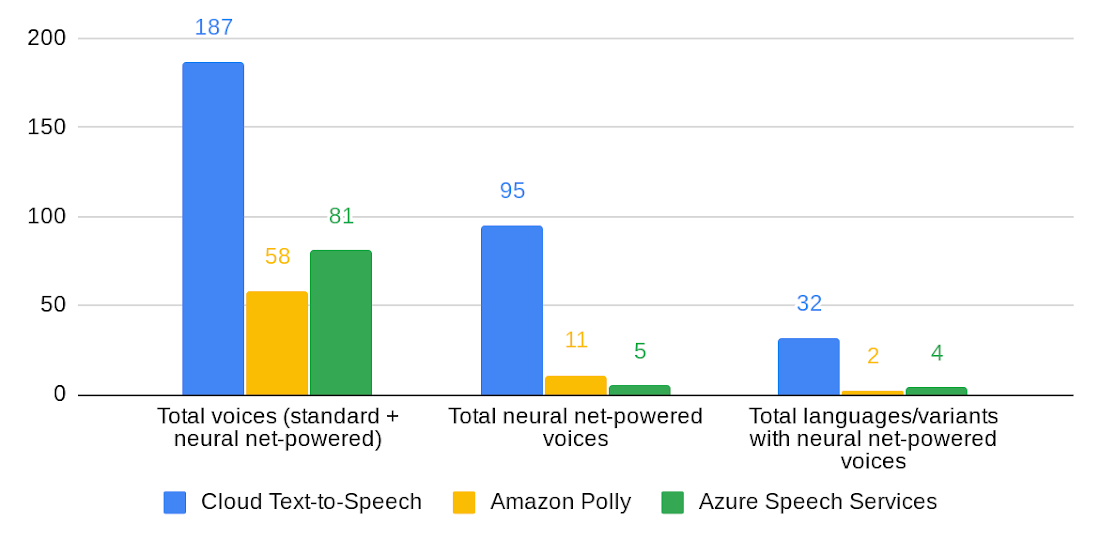
Source: cloud.google.com. Cloud Text-to-Speech expands its number of voices by nearly 70%, now covering 32 languages and variants.
Leave A Comment